Deep learning : le terme symbolise la grande espérance technologique du moment (et, dans les milieux spécialisés, commence à reléguer le « big data » à l’arrière-plan, même si l’un se conçoit très souvent avec l’autre). Tout semble destiné à être révolutionné par les réseaux de neurone artificiels « profonds ». Depuis peu, les robots savent reconnaître les images, maîtrisent le jeu de go à la perfection, rédigent plus vite qu’un secrétaire… Ils commencent même à rêver. L’application Deep Dream a fait fureur l’année dernière avec ses étranges compositions oniriques.

Sons, images, règles de jeu : rien n’échappe à la déferlante. Et quid du texte ?
Alors que la pratique du text mining prend de l’ampleur, notamment grâce la disponibilité d’immenses corpus numérisés et un contexte légal un peu plus arrangeant, l’apprentissage profond n’a pas encore intégré la boîte à outil des lecteurs distants. Les techniques courantes utilisés pour classer et arpenter les textes recourent pour l’essentiel à des modèles élaborés dans les années 1970-1990 : analyse de correspondance, analyse sémantique latente, SVM… Dans le champ des humanités numériques, l’innovation est plutôt d’ordre « documentaire » : comment appliquer des algorithmes éprouvés à de grands ensembles de textes ? Et comment en tirer des enseignements pertinents pour l’étude stylistique, littéraire, sociologique… des textes ?
Par exemple, l’étude remarquable de Ted Underwood et Jordan Sellers sur les « standards littéraires » dans les revues anglaises du XIXe siècle repose sur un détournement : le classement automatisé ne permet pas seulement de déléguer à la machine un travail d’étiquetage ; il contribue à reconstituer ce qui « fait genre » en identifiant des marqueurs lexicaux porteurs d’une intention de discours.
Une nouvelle application introduite en 2013 par Tomas Mikolov et al. augure peut-être de l’arrivée prochaine du deep learning dans les études textuelles et littéraires : Word2Vec. Word2Vec est très loin d’être parfait (et ne constitue pas, à strictement parler du « deep » learning). Tout en ouvrant manifestement des perspectives inédites et prometteuses, il reste encore très difficile d’en tirer un usage concret. Plusieurs projets de recherches en humanité numériques ont commencé à élaborer des implémentations (par exemple, en traçant l’usage des termes spécialisés de matériaux textiles dans le magazine féminin Vogue).
Pour cette petite présentation, je vais tenter d’aller au-delà (je ne serai pas le premier : Ben Schmidt ou Ryan Heuser ont déjà publié de bons essais en ce sens…). Je précise d’emblée que j’apporterai plus d’interrogations que de solutions — mais bon, c’est le lot de l’expérimentation à l’état brut…
Mes tests porteront exclusivement sur un corpus contenant la totalité des chroniques du compositeur Hector Berlioz dans le Journal des débats entre 1834 et 1861 (au total près de 400 articles, un peu plus d’un millions de mots). Ce n’est pas un choix au hasard : c’est en faisant un peu d’exploration libre autour de ce corpus que j’ai été amené à prendre conscience d’une propriété très intéressante de Word2Vec. Toutes les manipulations ont été effectuées à partir de l’extension de Word2Vec pour le langage python, Gensim (qui contient également de nombreuses autres fonctions très intéressantes pour la pratique du text mining). Contrairement à d’autres essais similaires publiés sur Sciences communes, je n’ai pas publié le code même si on en retrouvera des bouts qui traînent de-ci de-là : je suis encore loin d’être parvenu à un programme un tantinet cohérent et structuré… Pour ceux qui souhaiteraient quand même jouer un peu avec les données d’origine, j’ai déposé le fichier généré par Word2Vec sur Github.
L’art de traduire les mots en vecteurs…
Comme son nom l’indique, Word2Vec transforme les mots en vecteurs (ou, en français courant, en listes de nombres). Dans mon corpus, « Beethoven » est devenu :
-0.073912 -0.077942 0.244746 -0.235633 -0.052089 -0.228696 -0.294700 0.224995 -0.220984 0.009802 0.113246 0.172214 0.116851 -0.014701 0.272866 0.256256 -0.181295 0.167663 0.384452 -0.357031 -0.232429 -0.185704 0.063136 -0.235764 -0.394459 -0.024006 0.294152 -0.244346 -0.175500 -0.030211 0.102827 -0.067870 -0.329649 -0.267827 -0.239693 0.300108 -0.242601 -0.005308 0.234772 0.148167 0.041641 0.205686 -0.006405 -0.153118 0.245944 -0.101422 -0.204146 -0.215763 0.219858 -0.365411 -0.269319 -0.161473 -0.270557 -0.066371 -0.090772 0.207627 -0.064222 0.384351 -0.049304 -0.003502 0.046460 -0.241773 0.252691 0.135745 0.183757 0.064836 0.234710 0.246344 0.049769 -0.353813 0.024466 0.359923 0.254209 0.256462 0.199013 -0.058624 -0.214481 -0.117650 -0.043015 -0.347653 -0.029410 0.026260 -0.309258 -0.162839 -0.114093 0.382022 0.356538 0.352163 0.031176 0.186652 0.002508 -0.074699 -0.424376 -0.240450 0.065470 0.064408 -0.104289 -0.097309 0.265224 -0.248547
En apparence cette liste ne veut rien dire. Il s’agit d’une « réduction » des relations contextuelles qui relie ce mot entre eux. À mon avis le meilleur analogue se trouve du côté des techniques de réduction de la taille des fichiers1 . Lorsqu’on convertit un texte en fichier ZIP on parvient à le rendre beaucoup moins volumineux. Par contre, le contenu ne veut plus rien dire (tout en étant manifestement bien là : il suffit de « dézipper » le fichier pour le retrouver).
Les vecteurs constituent en quelque sorte des fichiers super-ZIP : la situation initiale du terme a disparu (ce qui fait qu’on ne peut pas reconstituer le texte) ; par contre, elle porte potentiellement de nombreuses informations sur les relations que ce terme entretient avec d’autre terme. On parle alors de word embedding. Il n’y a pas vraiment de traduction officiel de cette expression apparue en 2003 (on peut à la rigueur parler d’intégration de mot). La principale distinction avec les méthodes usuelles de text mining et de traitement automatisé sur langage naturel se joue en effet sur la connexion entre le mot et l’ensemble du texte : par contraste avec les tableaux classiques mots vs. documents, le mot se trouve « relocalisé » et inscrit dans le prolongement immédiat de ses « voisins », et non dans le continuum d’un document entier. Aux dernières nouvelles, ces words embedding font fureur dans les conférences américaines de linguistique computationnelle — et ont complètement relégué les techniques plus classiques à l’arrière-plan.
Il est ainsi possible de retrouver les termes les plus proches de Beethoven :
listBeethoven = model.most_similar(positive=['beethoven']) print listBeethoven >>>>>> [('mozart', 0.7579751014709473), ('weber', 0.7569864988327026), ('haydn', 0.7024569511413574)]
Il n’y a que des noms de compositeurs. Nous entrons ici de plain-pied dans une spécificité de Word2Vec : les liens ne sont pas entre des éléments de discours proches (ce qui amènerait par exemple à rapprocher Beethoven de « Fidelio » ou de « symphonie ») mais entre des éléments qui sont employés de la même manière. Il y a une certaine manière de présenter Beethoven dans les chroniques de Berlioz qui fait écho plus généralement à une certaine manière de présenter des noms de musiciens, voir des noms tout court, dans la langue française du XIXe siècle. Les words embedding conservent, sous une forme opaque, une sorte de contexte idéel, de moyenne des interactions locales entre un mot et les autres mots du corpus. Il faut se représenter l’action du réseau de neurone comme celle d’un sculpteur qui à partir d’un bloc de marbre indistinct (tous les vecteurs correspondent en effet à des séries de nombres aléatoires) parviendrait à modeler la morphologie relative de chaque terme, en les confrontant successivement avec tous ses voisins2 .
Word2Vec permet d’aller plus loin : retrouver des relations d’analogie entre les différentes entités. Nous pouvons ainsi indiquer au programme que les termes « Beethoven » et « Fidelio » entretiennent une certaine relation (celle d’auteur à œuvre mais j’insiste sur le fait que nous ne précisons pas laquelle) et que nous souhaiterions avoir une liste de terme qui sont liés de la même manière à « Weber » :
listBeethoven = model.most_similar(positive=['beethoven', 'fidelio'], negative=['weber']) print listBeethoven >>>>> ['freyschütz', 0.6202365159988403), ('symphonie', 0.584333062171936)]
Ce que « Fidelio » est à « Beethoven », « Freischütz » l’est à « Weber » : leur opéra le plus connu3 . La combinaison que je présente ici est une variante personnalisée de l’exemple classique du roi et de la reine. Dans n’importe quel texte suffisamment étendu (généralement la totalité de la version anglophone de Wikipédia), Word2vec parviendra à résoudre l’équation suivante :
Man – King = Woman – ?
? = « Queen »
J’ai intentionnellement maintenu les termes en anglais car je ne suis pas certain que la même combinaison marcherait en français, où « homme » reste encore parfois employé dans un sens générique (et, au fond, assez sexiste) comprenant les deux sexes.
L’équation est plus « facile » à comprendre si on se rappelle que chaque mot constitue un « contexte d’apparition ». « Beethoven – Fidelio » représente en quelque sorte la situation du terme « Beethoven » une fois qu’on lui a retiré son affinité (ou ses relations) avec « Fidelio » :4. Par conséquent, lorsqu’on retire du contexte moyen d’apparition de « Beethoven » les configurations qui impliquent également l’apparition de l’opéra Fidelio (ce qui nous limiterait plutôt, par exemple, aux phrases où l’on discuterait des sonates de Beethoven) on effectue une opération analogue au retrait des phrases ayant trait à Freyschütz dans le contexte moyen d’apparition de « Weber ». Dans les deux cas, le retrait se traduit apparemment par l’occultation de cooccurrences prédites liées à l’évocation d’un opéra.
Il est aussi possible de se la représenter dans un graphique (en réduisant les nombreuses dimensions de la liste de nombre à deux dimensions permettant d’établir des coordonnées). L’image ci-dessous représente plusieurs projections « géographiques » dans l’article original de Mikolov et al. : les capitales sont reliées à leurs pays.

Vers une exploration de l’espace sémantique du texte ?
Pour produire un tel résultat, Word2Vec emploie une machinerie compliquée, qui repose notamment sur un réseau de neurone artificiel en partie aménagé pour traiter du texte. À chaque mot est associé une série de mots voisins (généralement de 5 à 10) qui forment le « contexte ». Dès qu’un mot apparaît, le réseau tente de prédire les mots voisins ; selon l’étendue de l’erreur, il met à jour la représentation condensée du mot (la liste de nombres) et les réglages internes (les « biais » propres à chaque neurone et les « poids » propres à chaque relation entre neurone)5 .
Word2Vec n’utilise qu’une version légère (ou « shallow ») des réseaux de neurone artificiel : concrètement il utilise peu de couches successives de neurones se transmettant l’information. Cette limitation technique lui permet de fonctionner très rapidement (l’entraînement sur le corpus Berlioz a pris à peine dix secondes). Par contre, la montée en abstraction est bridée : Word2Vec ne cherche pas vraiment à dégager de grands principes ou de grandes notions structurant ce qu’il lit (comme le ferait spontanément un lecteur humain). L’objectif principal reste d’aboutir à une représentation des contextes d’apparition des mots aussi correcte que possible sans vraiment s’attacher à faire émerger des méta-relations abstraites (même si, comme nous le verrons après, elles émergent quand même un peu).
Depuis 2013, Word2Vec a suscité un grand nombre de publications (l’article d’origine a été cité plus de 2000 fois…). Certaines ont démontré qu’il n’était pas nécessaire d’utiliser des réseaux de neurones artificiels au fonctionnement opaque pour trouver à peu près le même résultat. Le programme GLOVE développé par Stanford repose ainsi sur l’utilisation de cooccurrences entre les termes (le nombre de fois qu’un terme apparaît en concomitance avec un autre). En croisant les probabilités de cooccurrence, il devient possible de reproduire exactement le fonctionnement de Word2Vec — et ce manière bien plus lisible.
Présentant une approche similaire, un excellent article d’Omer Levy et Yoav Goldberg conclut que Word2Vec constitue avant tout « une excellente manière de préserver des motifs inhérents à une matrice de cooccurrence ». Sous l’effet de cette opacité ressentie, le champ de recherche des « words embedding » tend aujourd’hui à s’éloigner des réseaux de neurone. La dernière création du concepteur de Word2Vec pour Facebook, FastText (divulgué pas plus tard qu’il y a deux semaines) semble ainsi évacuer totalement cette piste6 .
Pour l’heure, à l’exception de FastText (que je n’ai pas encore testé : il faudrait que je mette à jour ma version de C++), les alternatives actuelles à Word2Vec présentent l’inconvénient d’être coûteuses en infrastructures et/ou en temps de traitement. Pour construire les matrices de cooccurrences géantes de GLOVE, il est nécessaire de disposer de beaucoup de mémoire vive. C’est jouable à l’échelle de grands projets disposant d’infrastructures distribuées — mais comme la plupart des digital humanists, je n’ai que mon petit portable.
Je vais donc tenter une autre approche : tenter de faire la même chose pour Word2Vec que ce qu’Underwood ont fait pour les régressions logistiques. Alors que l’outil est explicitement conçu dans une optique « moteur de recherche », je vais essayer de lui soutirer autre chose : faire émerger les principaux groupes d’entités et les liens qui les caractérisent, soit les tensions sous-jacentes à l’espace « sémantique » du texte.
J’insiste ici sur cet aspect sémantique : l’enjeu n’est pas de tracer un certain régime de discours ou un certain ensemble stylistique mais des classements ou des ontologies sous-jacentes d’une certaine production textuelle. Ainsi, dans le cas du corpus des critiques de Berlioz, il y aurait de toute évidence une famille des compositeurs et peut-être une famille des dénominations musicales spécialisées (ou peut-être pas…) et ces différentes familles seraient liées ou non entre elles.
Bref, nous utilisons ici Word2Vec à l’envers : il ne s’agit pas de retrouver des termes en fournissant des analogies mais de dégager les principales séries d’analogies inhérentes au texte, sans les soupçonner à priori. Par ce biais, il deviendrait possible d’identifier les classements et les ordres jugés implicitement important par le texte lui-même. Alors que l’analyse des entités nommées reste focalisée sur les groupements qui intéressent directement les industries de l’information (personne, lieu, organisation), nous pouvons très bien imaginer de retrouver des groupements beaucoup plus précis et/ou exotiques (les idéologies, les émotions, les termes économiques ou médicaux spécialisés, les ingrédients de cuisine ou, pourquoi pas, les positions sexuelles…) sans émettre de préjugés a priori sur ce qu’ils peuvent bien être. Dans une synthèse détaillée de l’utilisation des Words Embeddings pour les humanités (qui présente également au passage une extension de Word2Vec pour R) Ben Schmidt parvient aux même conclusions :
Less flexible data models like topic models lock you into one particular idea of what Catholicism, or food, or any other topic, might be. WEMs, on the other hand, explicitly enable searching for relations embedded in words. If there’s a binary, it’s open for exploration.
En ce qui me concerne, l’idée m’est venue par hasard. J’utilise depuis quelque temps Word2Vec pour reconstituer des « réseaux de discours » : je relie chaque couple de terme présentant une affinité positive supérieure à 0,7 (enfin, selon les cas, ça flotte entre 0,6 et 0,8). Au sens large, ils tendent à se regrouper par type de discours (ce qui est assez logique vu que le « contexte » ne s’étend pas au-delà de dix mots) et nous parvenons à générer des réseaux de termes qui correspondent assez bien à ce que trouvent par ailleurs les bons vieux algorithmes de topic modeling. Dans ma thèse, j’ai ainsi utilisé cette méthode pour présenter visuellement la distinction entre les deux principaux sous-genres de la chronique boursière française à ses débuts : une chronique d’économie politique fortement influencée par le saint-simonisme et une série d’énoncés très formalisés sur l’évolution des cours (les actions de X sont à Y, et ainsi de suite).
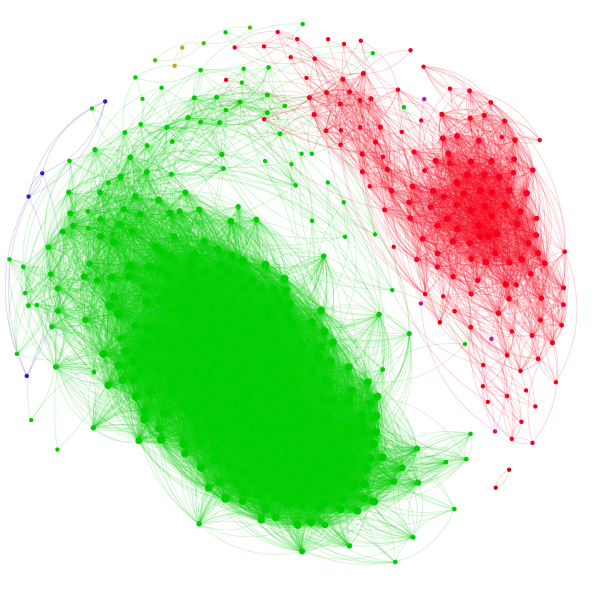
Lorsque j’ai appliqué le même traitement au corpus Berlioz en janvier dernier, j’ai été soudainement frappé par un ensemble surprenant :
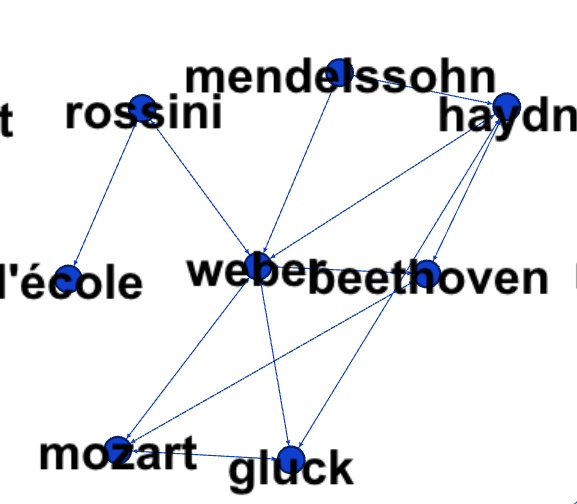 À l’exception de l’anomalie « l’école » (mais qui est cependant instructive…) tous les compositeurs se retrouvent hébergés dans le même réseau qui est coupé du reste. J’ai ainsi pris conscience que mon réseau ne représentait des types de discours que par accident (au niveau méta où les familles de termes tendent elle-même à s’agréger dans des systèmes de discours où elles s’illustrent préférentiellement). Le véritable échelon est sémantique : celui des groupements d’entités qui fait pour un texte comme une critique musicale, l’ensemble « compositeur » forme une distinction pertinente (alors que ce ne serait clairement pas le cas pour la chronique boursière formée à la même époque).
À l’exception de l’anomalie « l’école » (mais qui est cependant instructive…) tous les compositeurs se retrouvent hébergés dans le même réseau qui est coupé du reste. J’ai ainsi pris conscience que mon réseau ne représentait des types de discours que par accident (au niveau méta où les familles de termes tendent elle-même à s’agréger dans des systèmes de discours où elles s’illustrent préférentiellement). Le véritable échelon est sémantique : celui des groupements d’entités qui fait pour un texte comme une critique musicale, l’ensemble « compositeur » forme une distinction pertinente (alors que ce ne serait clairement pas le cas pour la chronique boursière formée à la même époque).
Essai de dégagement des ensembles sémantiques
Depuis lors, j’ai été en partie obsédé par l’idée de dégager spontanément ces ensembles sémantiques. La principale difficulté vient de la multiplicité des relations « encodées » par Word2Vec. Le terme « roi » peut ainsi correspondre au versant masculin de reine, mais aussi au supérieur du duc ou du comte… Il est difficile d’être certain de dégager a priori les ensembles sémantiques les plus pertinents — soit reflètent le mieux les classifications/ontologies sous-jacentes du texte.
J’ai utilisé ici plusieurs « trucs » :
(1) Un contexte suffisamment élevé (de l’ordre de 10 mots). Plus le contexte est faible, plus le réseau de neurone va se focaliser sur des relations syntaxiques (singulier/pluriel, masculin/féminin, passé/présent) qui se concentrent généralement dans le voisinage immédiat du mot (articles, verbe, préposition) ; plus il est élevé, plus les relations sémantiques vont prendre le dessus. Pour notre workflow, les relations syntaxiques présentent assez peu d’intérêt : Word2Vec n’est pas très bon à ce jeu là et nous utilisons déjà un outil plus efficace en (2).
(2) Un étiquetage syntaxique en amont. À chaque terme nous associons un type grammatical (nom commun, adjectif, verbe, nom propre). Pour ce faire, nous avons employé l’application Talismane développée par Assaf Urielli qui obtient de bon résultats pour le français. Nous obtenons un très long tableau répertoriant pour chaque occurrence du mot, son lemme, son type grammatical et tout un tas d’information (personne, genre, temps, etc.).
(3) Découper Word2Vec. L’étiquetage syntaxique permet déjà d’opérer une meilleur lemmatisation que celle présente par défaut dans les extensions de R ou de python : au lieu d’avoir des bouts de mots parfois mal coupés qui génèrent des ambiguïtés, nous obtenons directement les formes « de référence » (verbes à l’infinitif par exemple). Surtout, une fois que nous avons fait tourné Word2Vec sur le corpus lemmatisés, nous pouvons sélectionner les termes en amont afin de limiter les croisements non désirés. Nous avons ainsi exclusivement travaillé sur les noms communs et les noms propres en excluant d’emblée tout le reste.
(4) Élaborer une matrice des « affinités » sur l’ensemble des termes sélectionnés. Pour pouvoir calculer les affinités entre deux listes de nombres correspondant à chaque mot, Word2Vec fait appel à la mesure de la « distance cosine » (en gros à 1, les listes sont totalement identiques et à -1 elles sont totalement différentes). Comme je voulais faire les calculs en masse sur l’ensemble des noms communs, j’ai préféré faire appel à R plutôt que Gensim : il y a une charmante fonction « cosine » dans l’extension « lsa » qui établit d’un coup la matrice des affinités croisées entre chaque mot. Pour les noms propres, nous obtenons à terme, un gros tableau réciproque avec 1805 entrées et autant de colonnes. Afin de diminuer la taille de cette grosse matrice, nous nous sommes limités aux termes apparaissant plus de cinq fois (de toute manière, en-deçà de cette limite, Word2Vec commence à peiner à raccrocher le terme à un contexte pérenne).

(5) Projeter les principales relations dans un réseau. Nous utilisons un autre truc de R : la fonction « melt » de l’extension « reshape2 » qui permet de faire « fondre » une matrice. Toutes les colonnes deviennent des noms de variable ; toutes les valeurs migrent dans une colonne unique. Bref, nous avons l’architecture de base d’un graphe de réseau avec une source, une cible et une valeur indicative de la relation.
 Il suffit de rouvrir le document dans Gephi pour obtenir rapidement un réseau de bonne taille. Nous activons la reconnaissance des « clusters » et procédons au rapprochement des ensembles de nœuds liés… et voilà :
Il suffit de rouvrir le document dans Gephi pour obtenir rapidement un réseau de bonne taille. Nous activons la reconnaissance des « clusters » et procédons au rapprochement des ensembles de nœuds liés… et voilà :
Le graphe des noms communs comprend au total une petite dizaine de grands ensembles sémantiques. Nous allons successivement zoomer sur les principaux. Le gros ensemble du haut correspond clairement aux compte-rendu d’opéra (ce qui corrobore mon intuition que les ensembles sémantiques tendent à se recouper en ensembles stylistiques). Il se découpe en deux sous-ensembles : les personnages (en orange) et un magma plus indistinct comprenant les lieux les objets et, plus vaguement, des éléments d’intrigues (en rose). Même si on peut considérer que cette classification recoupe en partie les subdivisions classiques des analyses des entités nommées entre personnes et lieux, la tournure qu’elle prend est définitivement spécifique au corpus étudié : la nature des intrigues d’opéra est déterminante dans l’articulation entre les entités.
Un peu plus loin, nous glissons sur un groupement plus inhabituel (que je qualifierai de « sentiments »). À nouveau il ne s’agit pas de sentiments en général, mais bien de « sentiments dans la perspective d’une description de la réception musicale vers le milieu du XIXe siècle ». D’où le primat accordé à des qualificatifs ayant une connotation musicale intrinsèque (même si elle peut dériver vers le « sentimental ») : « harmonique », « accentuation », « lenteur », « intonation », « hardiesse »…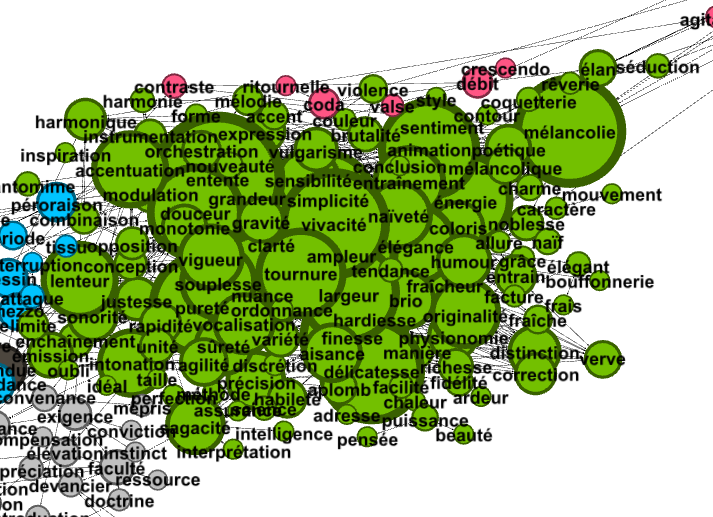
Un dernier ensemble intéressant a trait à la description musicale. Il se subdivise à son tour en des sous-ensembles plus nettement sémantiques : l’un, en bleu, est axé sur la description musicale formelle (d’où les notes et les qualificatifs spécialisés), l’autre (en gris) s’oriente vers la performance musicale. Il tend d’ailleurs à s’éfiler vers un autre mini-réseau (non représenté ici) où se concentrent les formes d’institutions (philharmonies, etc.).
Il est également possible de faire des « zooms » (même si ma méthode est pour l’instant un peu tortueuse : j’extrais la liste des mots intégrés dans les clusters de Gephi qui m’intéressent ; puis histoire d’approfondir un peu le réseau je reviens chercher des termes proches via Gensim). Pour les sentiments cela donne ceci :
On voit que le groupe peut être à son tour subdivisé en plusieurs sous-groupe selon que le sentiment vise à rendre directement compte d’une idée musicale (c’est très net en violet, en haut) ou qu’il s’inscrit dans la cadre d’une phraséologie romantique plus générale (le groupe en bleu plus foncé autour de « mélancolie » viendrait bien dans ce cadre).
Quelques perspectives
Au terme de cette petite exploration, je suis assez convaincu que les vecteurs de mots vont s’imposer parmi l’une des mesures privilégiées pour qualifier et documenter les textes. Même s’ils apparaissent opaques, ces réductions présentent les mêmes avantages que les fichiers ZIP : ils permettent de transmettre en prenant une place très réduite un grand nombre d’informations sur un corpus. Certains digital humanists ont déjà commencé à envisager ce tournant : Ryan Heuser (du Literary Lab de Stanford) vient de publier un fichier référençant les vecteurs correspondant à 150 000 ouvrages anglais du XVIIIe siècle ; il pèse 40 mo (alors que l’étalon du corpus d’origine doit être de l’ordre de la centaine de gigaoctet).
Je serai prêt à parier que dans les dix prochaines années, les langages de références d’éditorialisation scientifique des textes (comme TEI) intègreront des balises spécialisés pour relier des termes aux vecteurs de mots correspondants.
D’ici là, plusieurs problèmes (qui sont autant de défis) restent à résoudre :
1) Pouvoir comparer des vecteurs de mots distincts. C’est évidemment sympathique de pouvoir distribuer des représentations légères de corpus volumineux mais ce serait bien mieux d’arriver à les croiser. Si jamais je déportais mon attention sur la presse anglaise du XVIIIe siècle (cela m’est déjà arrivé ponctuellement par le passé…) je serai sans doute très heureux de confronter mes résultats avec ceux obtenus par Ryan Heuser sur la littérature de la même époque (ce qui permettrait notamment de différencier les ensembles sémantiques privilégiés par des productions textuelles différentes). Et c’est envisageable… depuis un mois (quand on vous dit que la recherche sur le sujet avance vite). Depuis le 8 août, un nouvelle recherche sur l’évolution du vocabulaire dans les corpus de Google Books présente une méthode pour recroiser des word embeddings issues de corpus distinct (apparemment ça marche même lorsque la méthode est différente). La manipulation porte le doux nom de Procruste Orthogonal et n’a pas l’air très compliquée à implémenter. Les programmes du projet ont été publiés sur Github (et incluent notamment une version en Python à destination de corpus de plus petite taille).

Il y a un corollaire à cette difficulté : résoudre l’ambiguïté des termes. Comme les applications utilisées travaillent à partir de mots bruts, il n’y a pas de ressources externes pour résoudre les homonymies et, plus largement, les polysémies. L’information est néanmoins vraisemblablement présente dans les word embeddings : l’extension de Ben Schmidt pour R inclut ainsi une fonction pour effectuer un « rejet du vecteur » ; ainsi pour le mot anglais « bank » qui indique aussi bien une rive qu’une banque, il est possible de corriger les données du vecteurs qui s’oriente vers la finance, et vice versa, pour aboutir à terme à deux vecteurs distincts. Schmidt présente une application très intéressante de cette fonction : évaluer l’influence du genre sur la signification de qualificatifs. L’image ci-dessous, un ensemble d’adjectifs similaires à bossy selon que les contextes « féminins » (marqués par l’utilisation de « her » ou « she ») sont conservés ou non. 2) Automatiser autant que possible l’ensemble du processus. L’essai de méthode que j’ai tenté de développer est problématique à cet égard : on passe par plusieurs couches d’évaluation probabiliste avec le risque de détériorer à chaque fois davantage les résultats (soit sucessivement : Word2Vec —> Talismane (pour la sélection, pas toujours parfaite des catégories grammaticales) —> Gephi (pour la détection des clusters de mots). Et le jugement humain est toujours nécessaire en sortie pour identifier à quelle « famille » les groupes d’entités correspondent. Pour cette dernière étape, je réfléchis actuellement à deux pistes :
2) Automatiser autant que possible l’ensemble du processus. L’essai de méthode que j’ai tenté de développer est problématique à cet égard : on passe par plusieurs couches d’évaluation probabiliste avec le risque de détériorer à chaque fois davantage les résultats (soit sucessivement : Word2Vec —> Talismane (pour la sélection, pas toujours parfaite des catégories grammaticales) —> Gephi (pour la détection des clusters de mots). Et le jugement humain est toujours nécessaire en sortie pour identifier à quelle « famille » les groupes d’entités correspondent. Pour cette dernière étape, je réfléchis actuellement à deux pistes :
- S’agissant des noms communs : confronter les termes à des ontologies comme Wordnet. Il devrait être possible d’indiquer a minima le champ lexical global des termes même si l’on perdra sans doute de l’information au passage (peu de chance de la dimension opéraique des clusters de lieu et de personne chez Berlioz soit réellement conservée).
- Pour les noms de personne, sous réserve qu’ils soient suffisamment connus, Wikidata pourrait faire l’affaire. Avec suffisamment de termes, il devrait être possible de contourner les homonymies (s’il existe clairement plusieurs Weber, le Weber entouré de Beethoven, Liszt et Haydn est très probablement le musicien).
Si j’insiste autant sur l’automatisation, c’est que je pressens que les words embeddings vont surtout trouver leur utilité dans les corpus peu étudiés. Leur apport pour comprendre l’écriture musicale de Berlioz (déjà bien connue) reste assez limitée. Par contre, ils peuvent constituer des outils d’exploration déterminants pour des collections méconnues. Or, c’est ce type de texte qui va graduellement irriguer le web à grande échelle : les journaux et les périodiques commencent tout juste à rentrer en masse ; dès que la reconnaissance des caractères sera au point (et, à nouveau, on attend les réseaux de neurones au tournant) on pourra s’attaquer peut-être aux archives manuscrites.
3) Ouvrir les réseaux de neurones et lever une partie de l’opacité entourant leurs méthodes de sélection. S’agissant de Word2Vec plusieurs initiatives ont commencé à s’y employer (j’avais un moment mis la main sur une amusante visualisation interactive en Javascript mais je n’arrive plus à la retrouver…). Dans le fil de mes analyses du réseau Berlioz, je me suis amusé à tenter d’évaluer les « affinités » entre les dimensions (arbitraires) du vecteur. Je soupçonne que, en accord avec l’architecture classique d’un réseau de neurones, chaque dimension pourrait être rattachée à un plus grand ensemble. L’illustration ci-dessous représente le résultat d’une matrice d’affinité non pas entre les mots mais entre les dimensions : même si l’ensemble paraît assez désordonné les affinités tendent à se grouper en « régions » de plus grande ampleur (pour clarifier ces clusters, les classes ont été ordonnées selon une mesure d’ordered dissimilarity image (ODI) inclue dans l’extension factorExtra de R).
 Pour approfondir la question, j’ai entrepris de sélectionner les mots qui avaient le plus haut coefficient au sein de certaines dimensions. Sans trop de surprise, on retrouve des thèmes cohérents (mais pas systématiquement). La dimension 8 stocke ainsi (en positif), une bonne partie du vocabulaire lié au champ lexical de « l’intrigue d’opéra » : main, amour, cœur, esprit, mort, ami, père, âme, fils, bruit, tour, côté, mariage, génie, frère… Par contre, l’axe positif/négatif de chaque dimension ne semble pas renvoyer à des sens concrets ou alors à la rigueur, selon une méthode parfois employée dans le topic modeling il fait allusion à des termes « repoussoirs » qui exclut l’activation de cette dimension. Au revers de la dimension 8, nous trouvons ainsi : mais, an, personne, en_outre, mois, dix, neuf, extrêmement, admirablement, rubini…
Pour approfondir la question, j’ai entrepris de sélectionner les mots qui avaient le plus haut coefficient au sein de certaines dimensions. Sans trop de surprise, on retrouve des thèmes cohérents (mais pas systématiquement). La dimension 8 stocke ainsi (en positif), une bonne partie du vocabulaire lié au champ lexical de « l’intrigue d’opéra » : main, amour, cœur, esprit, mort, ami, père, âme, fils, bruit, tour, côté, mariage, génie, frère… Par contre, l’axe positif/négatif de chaque dimension ne semble pas renvoyer à des sens concrets ou alors à la rigueur, selon une méthode parfois employée dans le topic modeling il fait allusion à des termes « repoussoirs » qui exclut l’activation de cette dimension. Au revers de la dimension 8, nous trouvons ainsi : mais, an, personne, en_outre, mois, dix, neuf, extrêmement, admirablement, rubini…
Si le réseau pouvait également nous envoyer directement des signaux de bas niveau, l’automatisation du processus deviendrait sans doute plus fiable : au lieu de reconstituer des « clusters » a posteriori sur Gephi on pourrait simplement récupérer ceux qui étaient déjà là a priori.
4) Et le deep learning ? Comme je le précisais déjà plus haut, Word2Vec ne représente que du shallow learning (de l’apprentissage léger avec peu d’étapes intermédiaires). Le deep learning appliqué au texte reste pour l’instant de l’ordre de la perspective inaboutie. le véritable défi consisterait à développer des interfaces adaptés. Pour les images, l’architecture actuellement utilisée (et initialement développée par Yann Le Cun) est très spécifique : l’unité de départ est un carré de x sur y pixels, soit littéralement un morceau d’image.
Word2Vec ne pioche pas véritablement de morceau de textes : s’il y a des bouts de contexte (les séries de 5 à 10 mots), l’ordre dans lequel les mots apparaissent n’a aucune importance. Une partie des recherches actuellement en cours visent à intégrer au moins la dimension du « paragraphe » comme entité signifiante ; FastText intègre de son côté un système parallèle de reconnaissance syntaxique (en conservant des subdivisions du mot de plus bas niveau, de 3 à 6 lettres).
Il serait sans doute souhaitable d’intégrer encore d’autres dimensions du texte, telles que la syntaxe (vu que les réseaux de neurone ne brillent pas spécialement dans ce domaine), les entités nommées (lorsqu’elles sont correctement étiquetées, comme le permet le langage TEI), les structures éditoriales (titre, page, chapitre, section…), le voisinages des images (avec, pourquoi pas, des systèmes de reconnaissance d’image et de texte fonctionnant en synergie), voire le vaste monde des métadonnées (ce qui prendrait tout son sens pour étudier des corpus composites comme la presse où cohabitent auteurs, sociabilités et régimes de discours éminemment distincts…).
Évidemment l’intégration de tous ces éléments requerrait des architectures bien plus complexes reposant par exemple sur l’articulation de plusieurs couches distinctes de neurones en entrer,. Et pour de ce texte « riche » des enseignements suffisamment cohérent, nous n’avons sans doute pas trop le choix que de gagner en « profondeur », de faire circuler l’information au travers d’un grand nombre de couches de neurones et, par généralisations successives, aboutir à des vecteurs de mots sans doute beaucoup plus riches et pertinents que ceux dont nous disposons aujourd’hui.
- En fait il s’agit d’un peu plus qu’un analogue : l’une des techniques fondamentales de réduction, le codage de Huffman, se retrouve dans Word2Vec afin de diminuer les temps de traitement pour les termes les plus courants
- Je ne vais pas rentrer dans ces détails, mais il convient de signaler que pour mener à bien ce processus de sculpture, Word2Vec peut utiliser deux modèles différents : le « sac de mots » (où un mot est prédit à partir de ses voisins) et le skip-gram (qui marche à l’inverse : un mot doit prédire ses voisins).
- En toute honnêteté, la liaison ne marche à tous les coups : ici j’ai utilisé un modèle avec un « contexte » de 5 mots (sur cette histoire de contexte, voir plus loin…) ; avec 10 mots, cela ne marchait plus. Cette variabilité des résultats est l’une des principales faiblesses de Word2Vec
- Je simplifie volontairement : il ne s’agit pas d’une soustraction simple
- Pour une description très détaillée du fonctionnement des réseaux de neurones artificiels je recommande l’excellent Neural Network and Deep Learning de Michael Nielsen. À noter que, le ratio de mot activés/mots passifs étant très faible pour chaque série contextuelle, Word2Vec emploie un modèle probabiliste : les 5 à 10 mots vont être confrontés à une série de mots prise au hasard. Comme l’opération est renouvelée à plusieurs reprises (on parle alors d’epochs), cette sélection aléatoire en vient à constituer une représentation valable du corpus en général…
- Ce n’est pas dit clairement mais dans le corps de l’article la nouvelle méthode est contrastée avec les réseaux de neurones